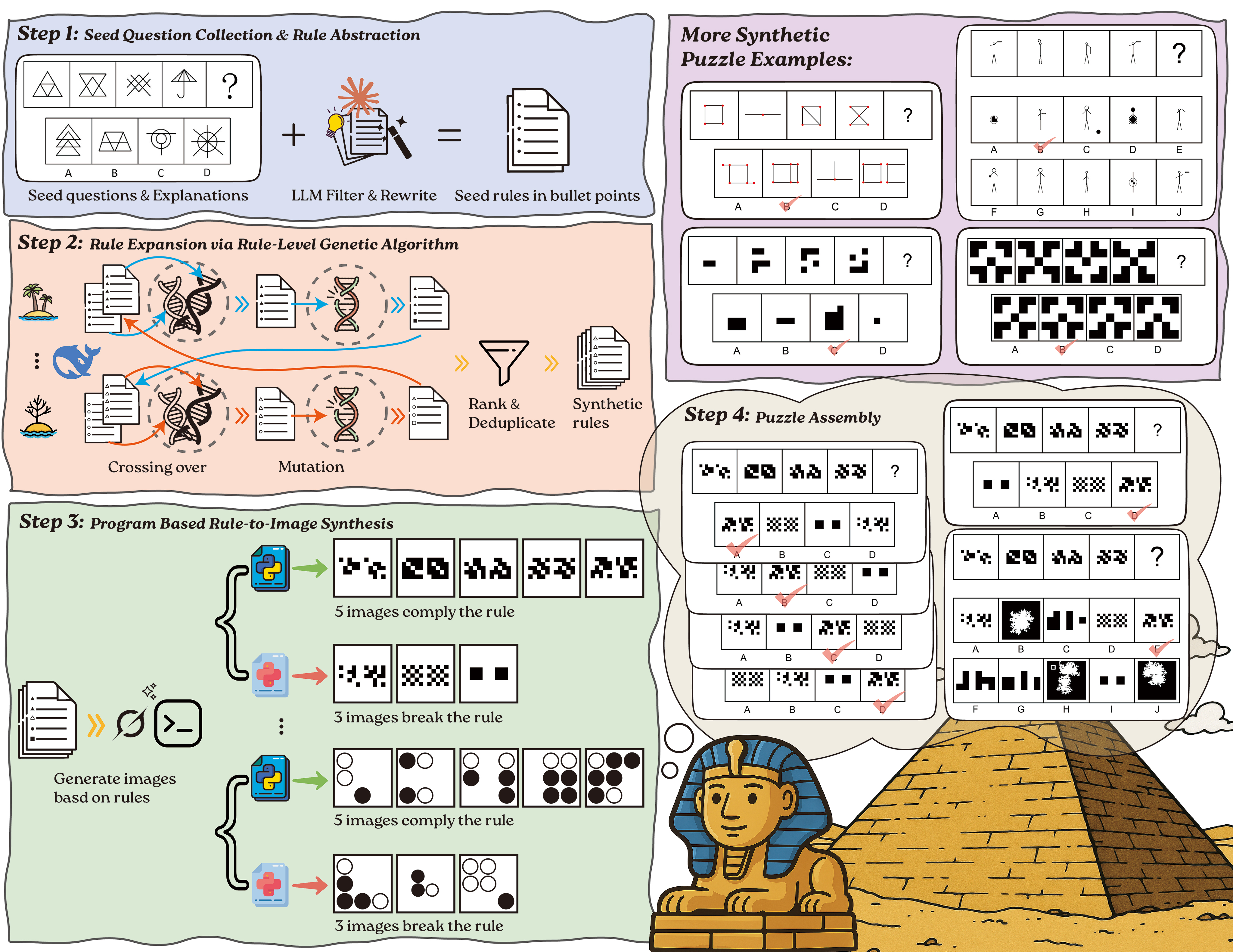
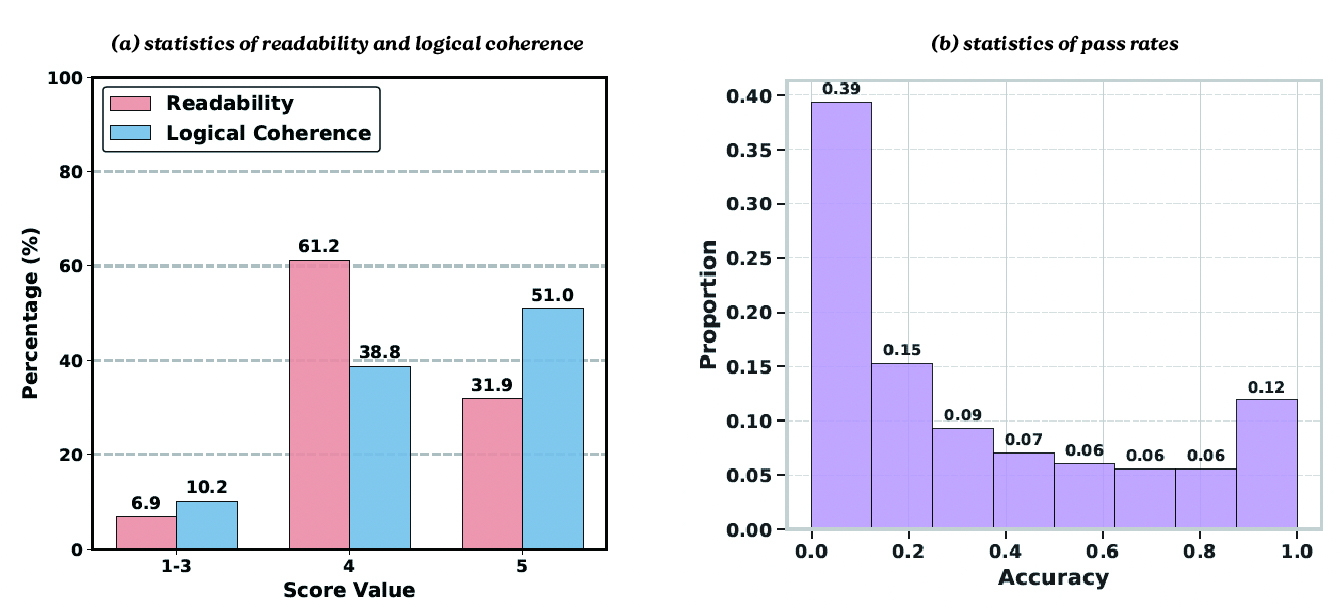
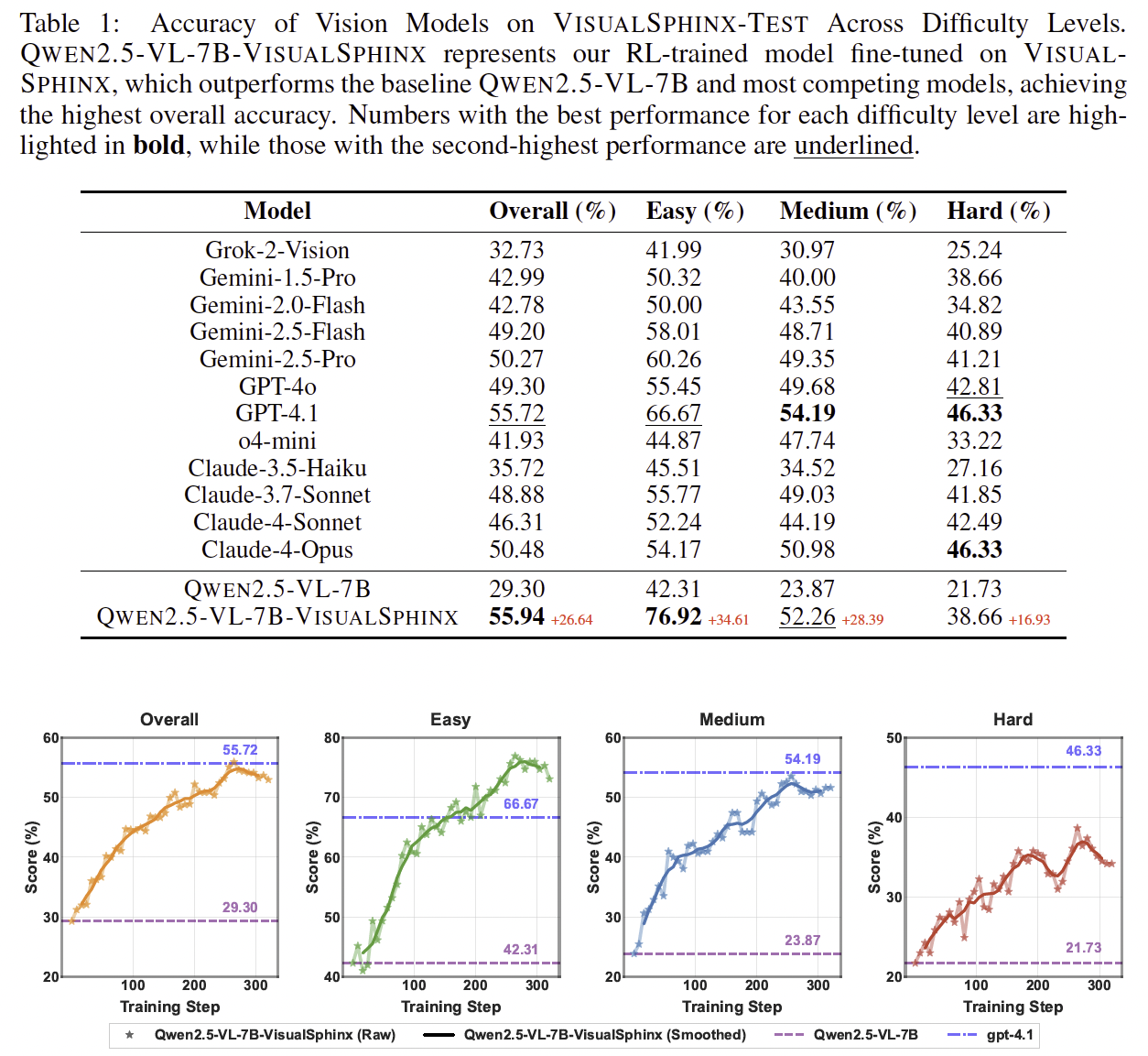
VisualSphinx Examples
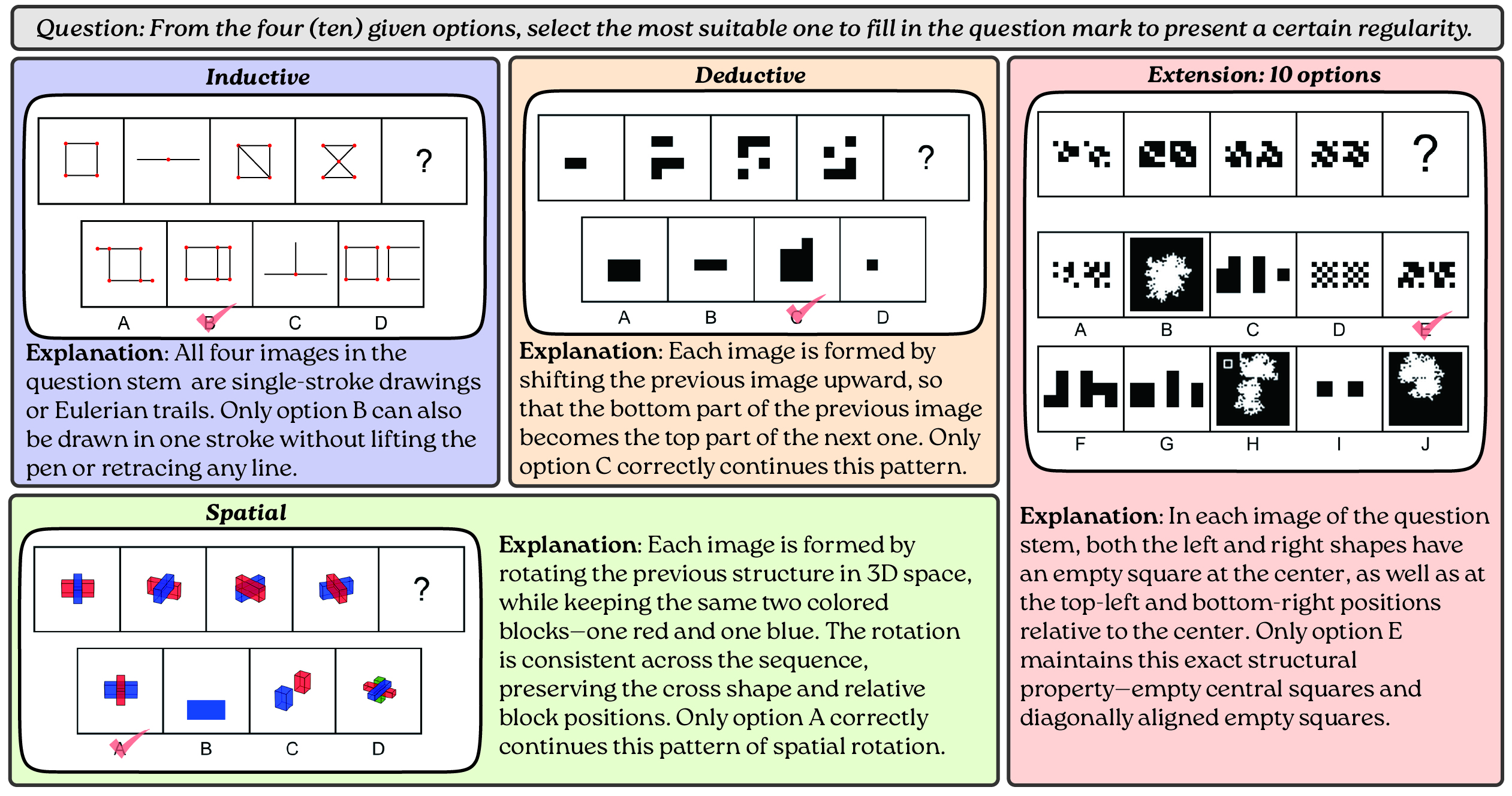
This figure demonstrates the VisualSphinx-V1 instances within each reasoning category. Each visual logic puzzle comprises a text prompt, a graphical question stem with four images and a question mark, and four candidate choices of graphical answers.